See the original problem on HackerRank.
Warning: HackerRank has recently changed the constraints of the problem by allowing duplicates. This change invalidated a couple of our solutions. This is discussed in the post.
Solutions
We found many solutions to this challenge.
Naive solution
|
|
The brute force \( O(N^3) \) solution does not work for all the test cases, so we need to somehow exploit the structure of the problem.
Our solutions are based on the observation that given an element of the triplet we can easily search for the other two, given that:
\( a_j - a_i = a_k - a_j = d \)
So if we go over all the elements and imagine to have found \( a_i \), we can seek \( a_j \) as \( a_i + d \) and \( a_k \) as \( a_i + 2d \).
Binary Search
Since the sequence is increasing, we can use a binary search:
|
|
Smarter Binary Search
A possible optimization works only on the original version of the problem: no duplicates allowed (the sequence is always increasing).
We reduce the span of the two binary searches: as you see, in the code above we do two binary searches on the whole array every time. Instead of seeking for \( a_j \) and \( a_k \) we can imagine to have found \( a_j \) and seek \( a_i \) and \( a_k \). Since \( a_i \) has to be on the left and \( a_k \) on the right, \( j \) becomes a sort of pivot and cuts the search space:
|
|
Clearly, the solution above does not work correctly when duplicates are in the array because for any \(a_j\) we can have more than one \(a_i\) and/or \(a_k\).
Functional-style Not-so-brute Force Search
Rewriting the concepts of the previous solutions, we can write a more efficient, but still more or less brute-force approach. However, this solution is fast enough to pass all the tests.
Like many functional expression, this one is better when commented inline:
|
|
Reducing the number of elements in the intermediate lists cuts the constant part of the O(N^3) complexity of this implementation enough to pass all the test. The worst case for this algorithm would be a very large number of identical elements, that would make the takeWhile operation ineffective.
Anyway, this implementation passes all the tests, and correctly manages duplicate elements.
Linear (not in general)
If the problem does not allow duplicates, we can exploit the fact that \( d \) is small (at most 20). Then for each beautiful triplet the distance between \( a_i \) and \( a_k \) is 2d. This means that found \( a_i \), we can seek \( a_j \) and \( a_k \) at most in 40 steps. This results in a constant for the problem.
Notice that the value of \( d \) is small, and recall that the input will always be in increasing order; because the input must be increasing, then a valid \( a_j \) will never be more than \( d \) indices to the right of \( a_i \), and a valid \( a k \) will never be more than \( d \) indices to the right of a valid \( a_j \) (or \( 2 \times d \) indices to the right of a corresponding \( a_j \). So, for each \( a_i \), the value \( a_j + d \) can only exist between indices \( i \) and \( i + d \) m and the value \( a_i + d + d\) can only exist between index \( i \) and index \( a_i + d + d\). You can just loop over this reduced range and check if the values exist.
So, the following code is linear:
|
|
Or in python:
|
|
Clearly we are exploiting a shortcut of the problem here. If \( d \) grows to \( N \), the solution turns into quadratic.
Really Linear
A 100% linear solution (working with duplicates too) comes with extra space. You know, sometimes space and time are interchangeable. To get rid of the lookup time, we can use a frequency table to store if a certain number occurs. This way seeking for any number (e.g. \( a_i + d \)) would result in constant time, reducing the total cost to \( O(N) \) (we still need to iterate all the elements):
|
|
We can afford this solution because the domain is quite little.
We may use std::unordered_set to save some space. std::unordered_set is
implemented with hash set (average constant-time complexity).
But, depending on the input, we may waste most of the time creating the set.
|
|
A similar approach in Python:
|
|
Frequency table with patterns
Another way of seeing the solution with a frequency table is thinking in terms of “sliding windows”.
Suppose we have this frequency table:
|
|
Where the first element is the freqency of 0. Suppose d=3.
Beautiful triplets are all triplets at a distance d. We can set a “sliding window” at the elements:
|
|
This means we do not have such a triplet.
Then we move the window by one position:
|
|
In this case we find something. In particular, we can do \(2 \cdot 1 \cdot 1\) triplets.
And so on.
Do you see the pattern?
It’s like zipping the frequency table with itself shited by d and with itself shifted by d+d:
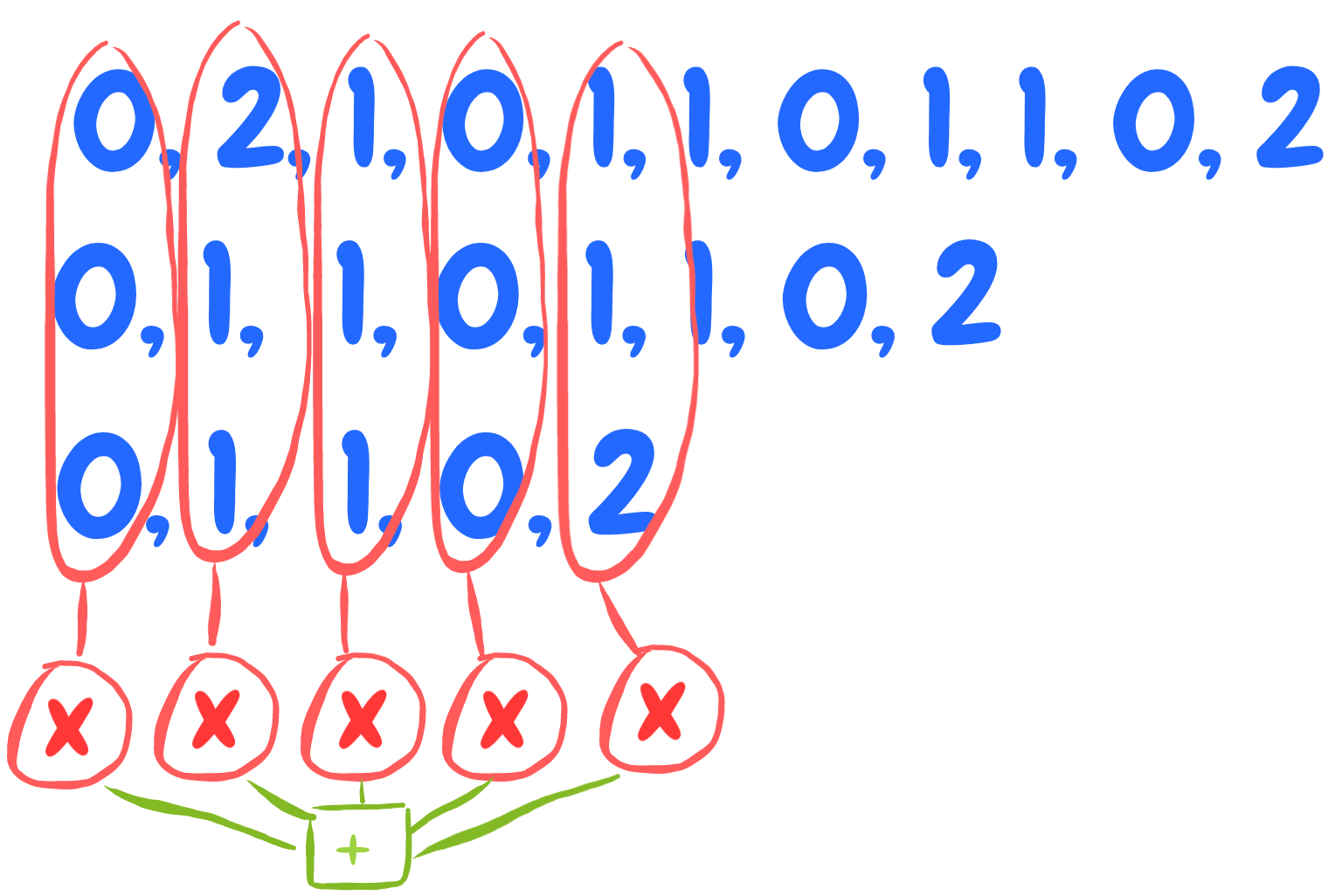
Here is an implementation in Python:
|
|
Here is a possible implementation of the solution above with C++20 ranges:
|
|
Exploting some metaprogramming, we can generalise the calleble into transform:
|
|
Benchmark
See here a quick benchmark of some of the previous solutions (the domain is a bit different).
Try increasing \( d \) and see how LinearDSmall gets worse.